jarak biaya adalah "gagasan keluarga metrik jarak alternatif" . Ada banyak cara untuk mengukur jarak antara dua titik yang relevan dengan GIS, termasuk Euclidean distance (garis lurus yang tidak dibatasi), Geodesic distance (ketika perjalanan dibatasi ke permukaan bola), dan network distance (saat perjalanan dibatasi ke jaringan linear). Jarak biaya menggunakan prinsip geografis Gesekan Jarak, yang menyatakan bahwa ada biaya atau impedansi yang terkait dengan pemindahan jarak unit ke lokasi mana pun, dan biaya ini bervariasi untuk ruang (dan dengan demikian dapat dikonseptualisasikan sebagai bidang). Misalnya, jika biaya seseorang yang melakukan perjalanan di ruang mana pun diukur ketika jumlah energi yang dikeluarkan, maka bergerak di atas air (mis., Berenang) memiliki biaya yang jauh lebih besar daripada bergerak di atas tanah (mis. Berjalan). Jika seseorang ingin meminimalkan biaya pengeluaran energi ini, maka mungkin lebih baik berjalan di sekitar badan air daripada berenang langsung melewatinya, meskipun jarak sebenarnya lebih besar. Biaya ini dapat diukur dengan berbagai cara. Meskipun pengeluaran finansial aktual dapat menjadi bagian darinya, gagasan "biaya" biasanya digunakan untuk setiap dampak negatif pindah ruang. Bergantung pada aplikasi tertentu, ini dapat mencakup:
- Waktu perjalanan
- Pengeluaran energi untuk perjalanan (misal : Penggunaan bahan bakar kendaraan)
- Biaya perolehan properti
- Biaya konstruksi
- Dampak negatif terhadap lingkungan alam (mis., Melintasi lahan basah atau membuka hutan)
- Dampak negatif terhadap lingkungan manusia (mis., Menghancurkan rumah atau bangunan bersejarah)
Secara konseptual, seseorang dapat "mengukur" biaya jalur yang melintasi area unit ruang mana pun. Sebagai contoh, jika seseorang merencanakan jalur bersepeda beraspal, lokasi pada lereng berhutan curam kemungkinan akan berarti biaya konstruksi yang tinggi, dampak negatif yang tinggi terhadap lingkungan alam, dan biaya energi yang lebih tinggi untuk pengendara yang mencoba bersepeda di lereng. Atau, tanah kosong di lingkungan pinggiran kota yang datar akan memiliki biaya rendah dalam tiga hal ini, tetapi tanah mungkin lebih mahal untuk dibeli. Karena biaya yang berbeda ini menggunakan unit ukuran yang berbeda atau tidak dapat diukur secara langsung dengan cara kuantitatif apa pun, model Indeks sering digunakan untuk membangun "ukuran semu" dari total biaya untuk digunakan dalam GIS.
Seperti banyak bidang lainnya, biaya biasanya direpresentasikan dalam GIS menggunakan kisi-kisi raster yang dikenal sebagai permukaan Biaya, di mana nilai setiap sel mewakili total biaya perjalanan ke segala arah melintasi area persegi yang dicakupnya. Grid raster ini biasanya dibuat dengan menerapkan model Indeks menggunakan aljabar Peta untuk menghitung total biaya dari raster terpisah yang mewakili elemen biaya individual. Dengan demikian "jarak" antara dua titik di sepanjang tambalan yang diberikan adalah akumulasi dari semua biaya yang relevan untuk setiap titik di jalan. Pada contoh jalur sepeda, jalur di atas bukit mungkin memiliki jarak biaya yang sama dengan jalur yang mengelilingi bukit, meskipun jalur sebelumnya adalah garis lurus pada peta.
Analysis Tools
Sebagian besar perangkat lunak GIS berisi sejumlah alat untuk melakukan berbagai tugas yang tergantung pada biaya dan jarak biaya ke dalam akun. Sebagian besar alat ini memerlukan satu untuk pertama kali Cost surface menggunakan alat GIS lain seperti Map algebra.
COST DISTANCE
The cost distance tool mirip dengan Euclidean distance raster tools, tetapi alih-alih menghitung jarak aktual dari sel yang diberikan ke seluruh sel, alat jarak biaya menentukan jarak tertimbang paling pendek (atau akumulasi biaya perjalanan) dari setiap sel ke lokasi sumber terdekat. Alat-alat ini berlaku jarak dalam satuan biaya, bukan dalam satuan geografis. Alat jarak biaya membutuhkan satu atau lebih lokasi sumber dan raster biaya sebagai input. Setiap sel dari grid jarak biaya yang dihasilkan berisi total biaya minimal untuk melakukan perjalanan dari lokasi sumber yang diberikan ke sel itu.
Secara bersamaan, alat ini menciptakan grid raster kedua yang dikenal sebagai raster backlink yang mengkodekan, untuk setiap sel, arah ke sel tetangga dengan biaya terendah (yaitu, di mana jalur berbiaya terendah akan datang dari untuk sampai ke sel ini). Biasanya nilainya adalah arah yang dikodekan, seperti angka antara 0-7.
Algoritma brute-force dasar untuk menghitung jarak biaya adalah sebagai berikut,
pada dasarnya menyebar dari sumber untuk mengisi seluruh grid:
- Buat daftar sel untuk dievaluasi, awalnya terdiri dari sel yang sesuai dengan lokasi sumber yang diberikan.
- Untuk setiap sel dalam daftar:
- Jika itu adalah sel sumber, tetapkan biaya 0
- Jika tidak, lihat 8 sel tetangganya dan identifikasi tetangganya dengan biaya terendah.
- Tetapkan nilai sel dalam raster backlink dengan kode untuk tetangga berbiaya terendah
- Tambahkan nilai untuk sel ini dalam raster biaya ke biaya tetangg (kalikan dengan 1,414 untuk diagonal diagonal).
- Identifikasi tetangga yang memiliki nilai lebih tinggi dari sel ini atau tidak ada nilai sama sekali dan tambahkan mereka ke daftar.
Algoritma ini agak tidak efisien, di mana banyak sel akan ditambahkan ke daftar,dan dengan demikian dievaluasi berulang kali. Beberapa algoritma yang lebih efisien telah dikembangkan.
Cost Path Analysis
Setelah jarak biaya dan raster backlink dibuat, jalur dengan biaya terendah dapat dibuat antara sumber dan satu atau lebih tujuan, dengan melacak kode arah backlink kembali dari tujuan kembali ke sumber.
Cost-Based Allocation
Alokasi Biaya membuat kisi-kisi raster di mana setiap sel dikodekan dengan sumber mana (dengan asumsi banyak sumber disediakan untuk alat) dapat dicapai dengan biaya minimum. Dengan demikian, raster alokasi yang dihasilkan terdiri dari daerah di sekitar masing-masing sumber. Dengan demikian alat ini analog dengan diagram Voronoi untuk jarak euclidean, dan alat alokasi Lokasi untuk jaringan.
Corridor Analysis
Analisis Koridor mirip dengan Analisis Jalur Biaya, tetapi alih-alih mengidentifikasi rute optimal tunggal antara dua titik, analisis ini dapat mengidentifikasi semua rute yang berada di bawah ambang biaya tertentu. Ini biasanya mengambil bentuk petak luas wilayah antara sumber dan tujuan, sebagai lawan dari jalur sel satu. Pendekatan ini paling berguna untuk aplikasi di mana jalur tunggal tidak perlu dipilih, hanya area umum jalur yang dapat diterima, seperti dalam pemodelan migrasi satwa liar.
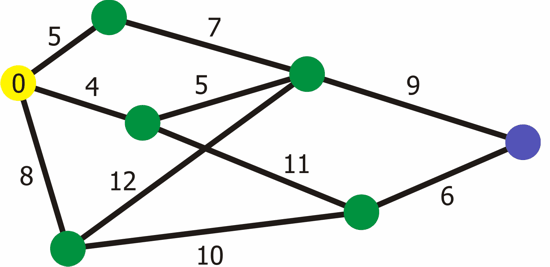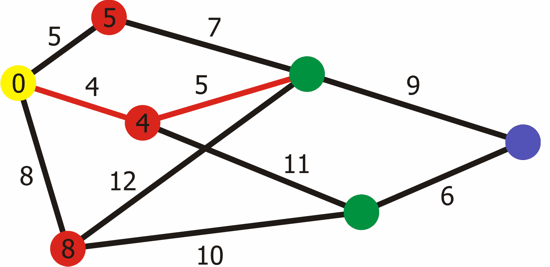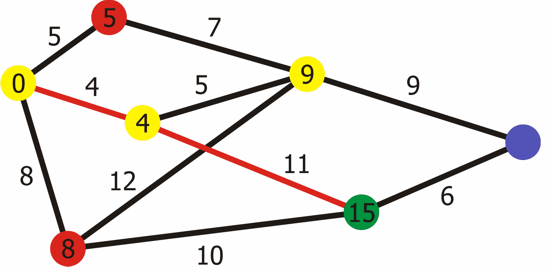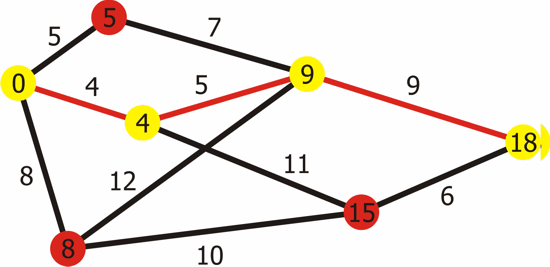
Cara untuk melakukan Cost Distance